That’s news to me… I have seen a lot of threads about problems with the AS5047p but I fail to find one with a solution.
interesting re. the differential transievers! Although I am struggling to make it work even with wires <10cm - it’s infuriating because as I say, it used to work fine over several metres of cabling.
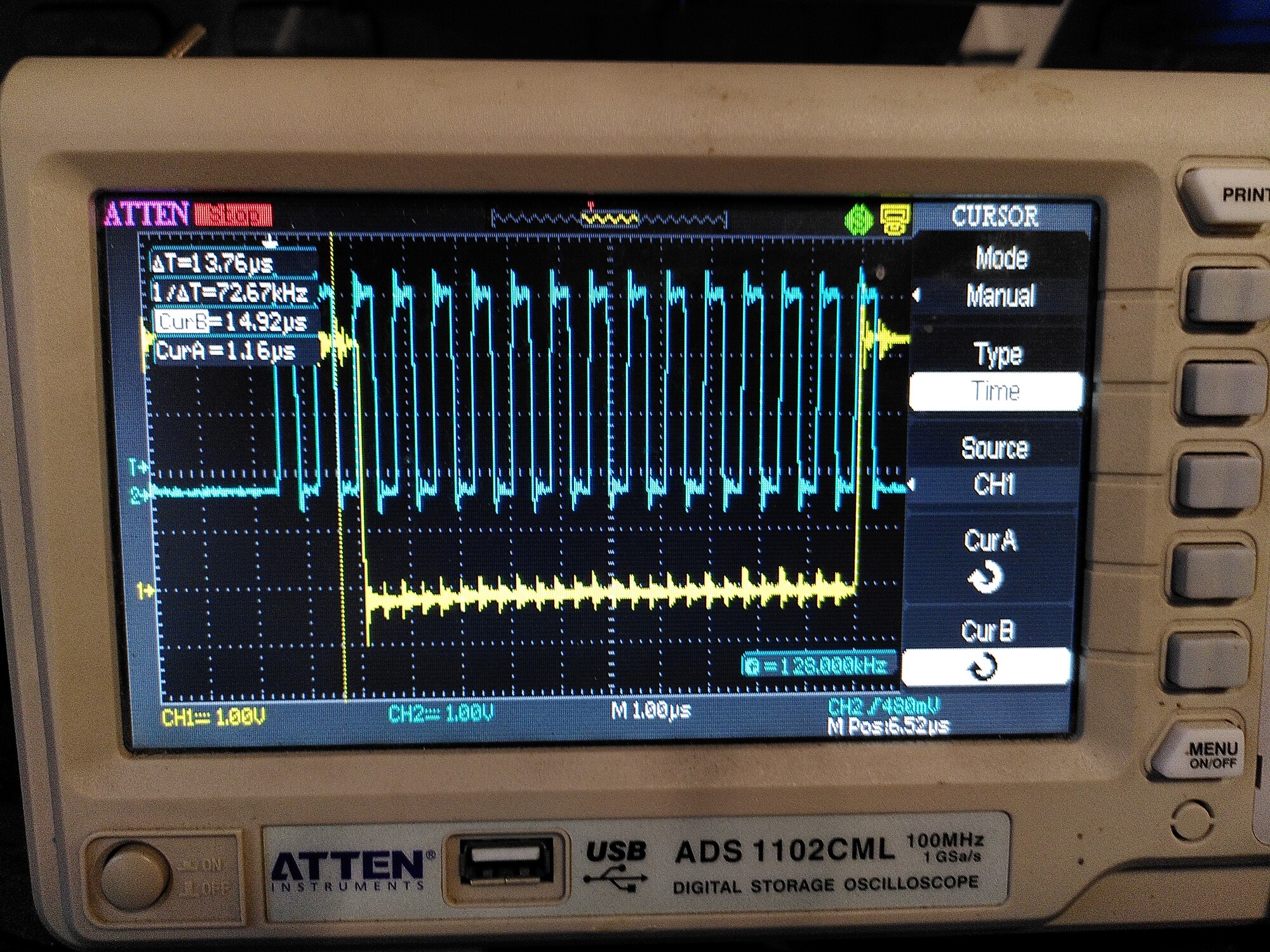
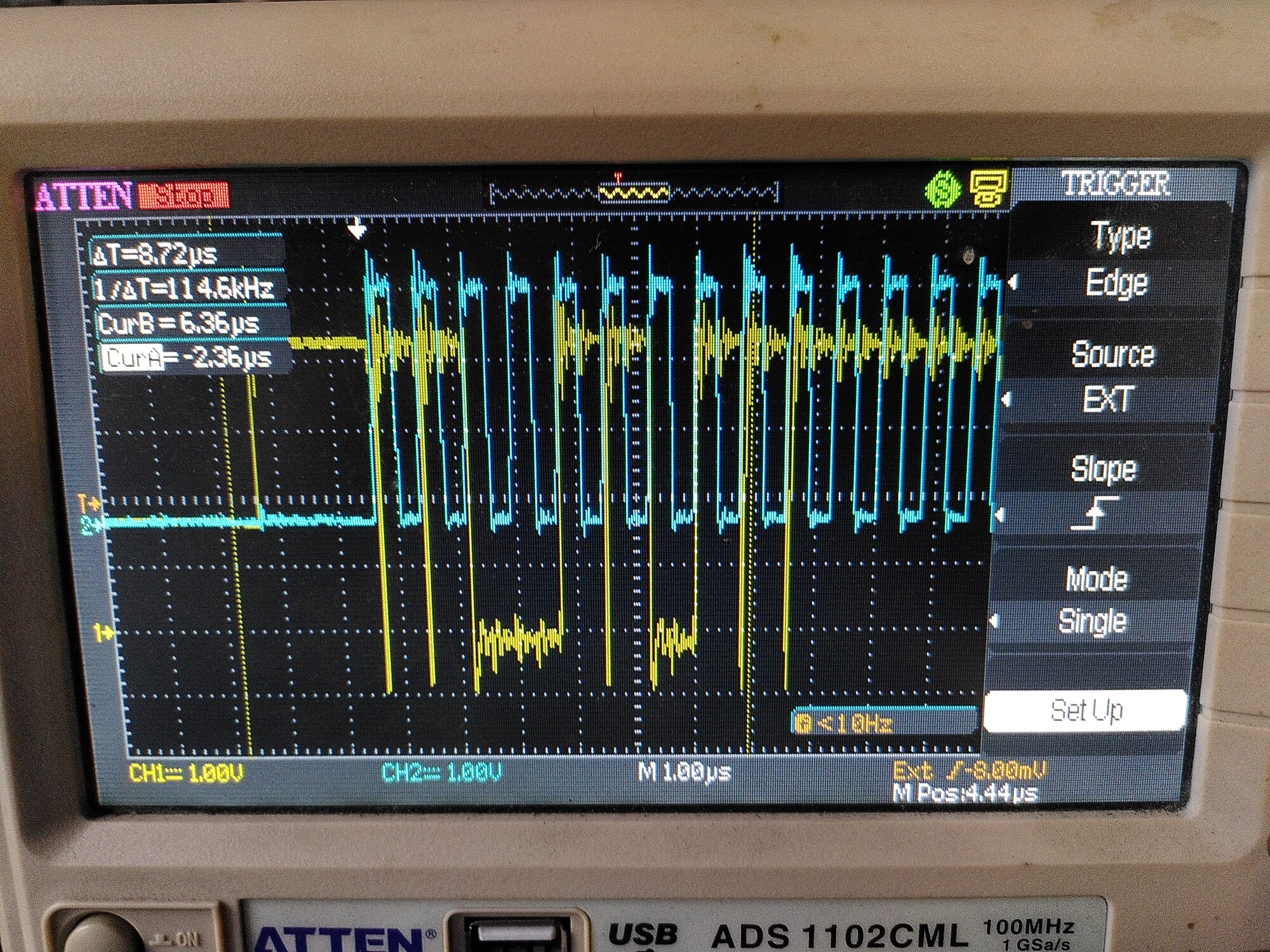
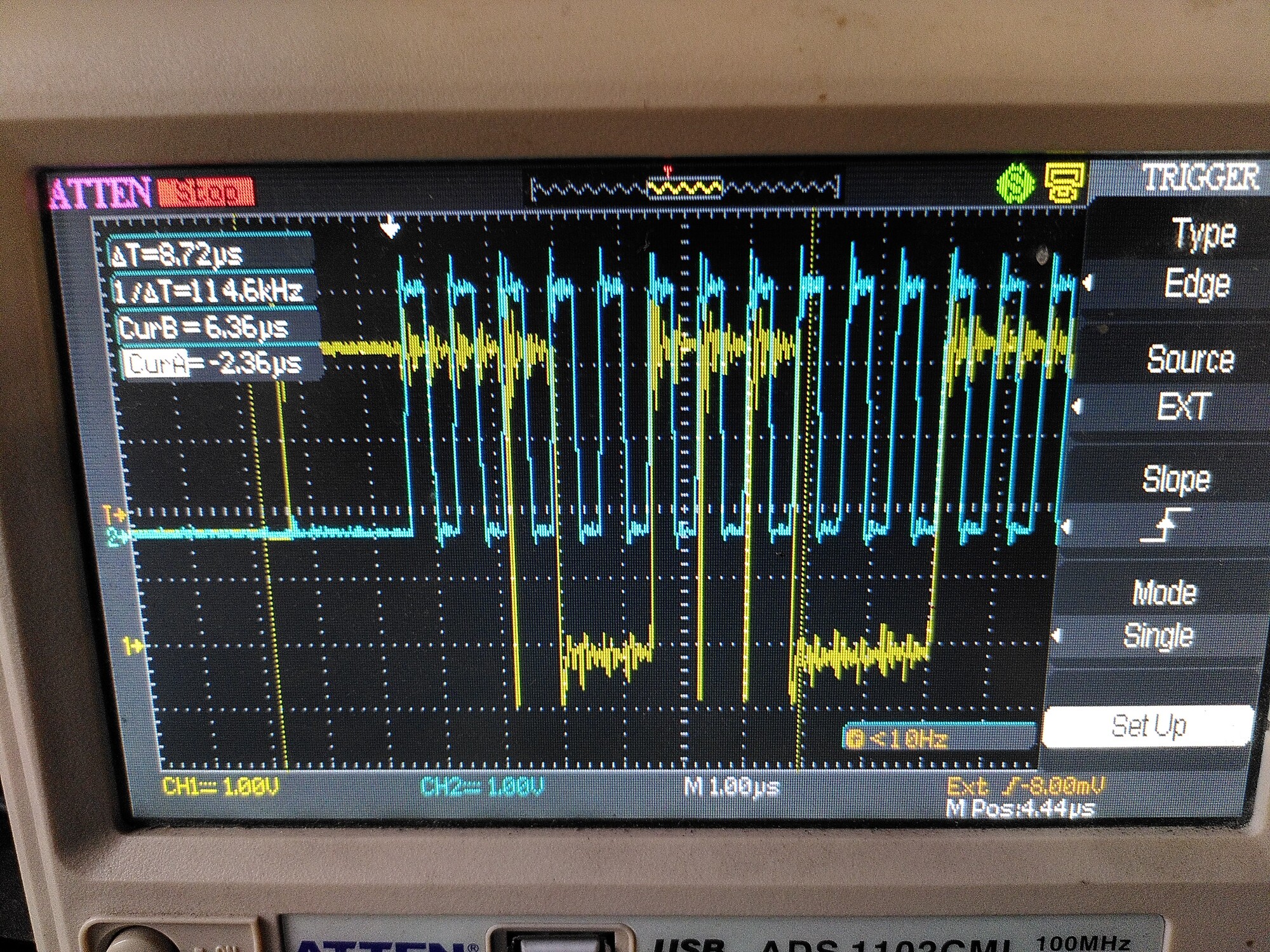
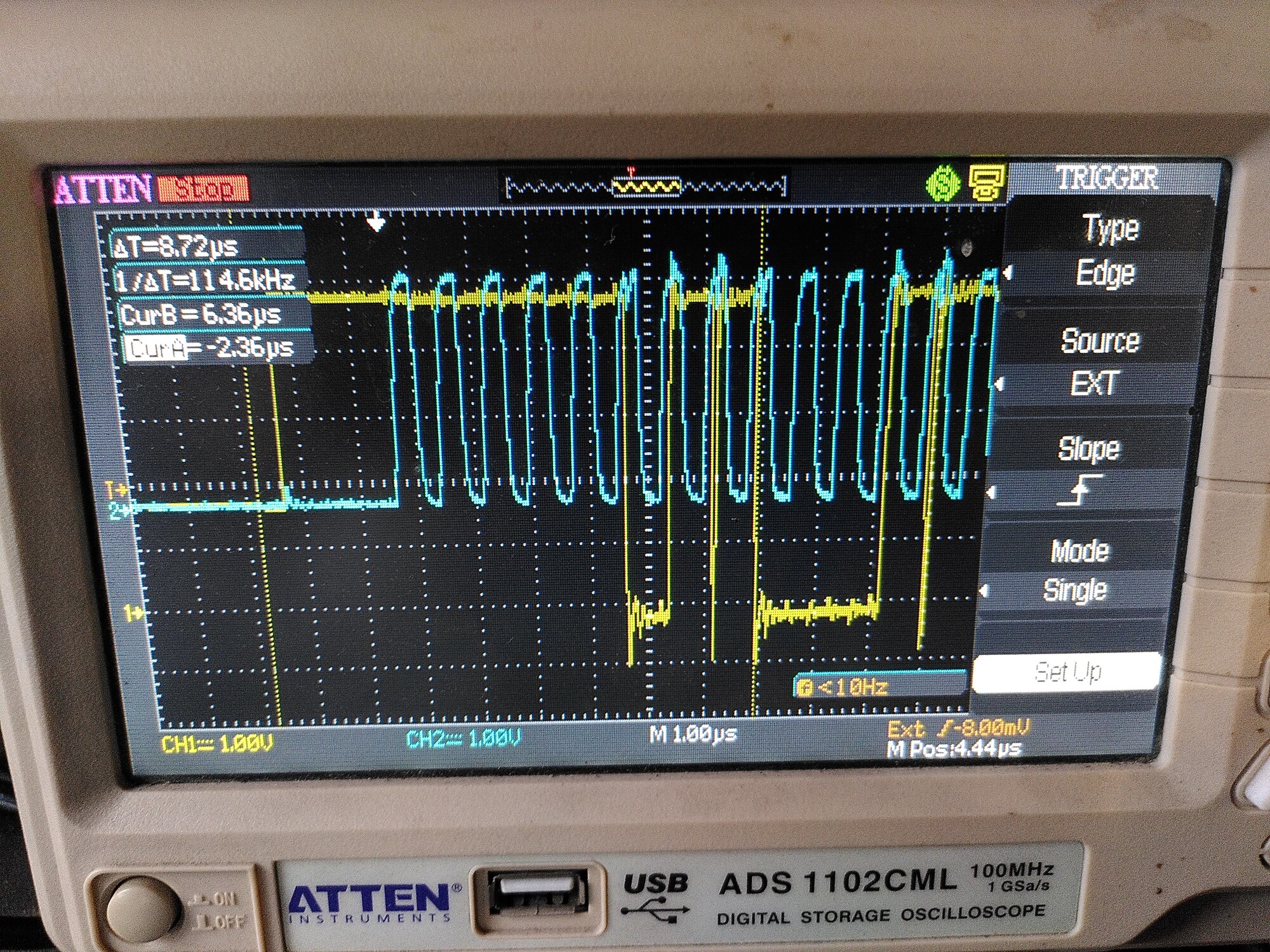
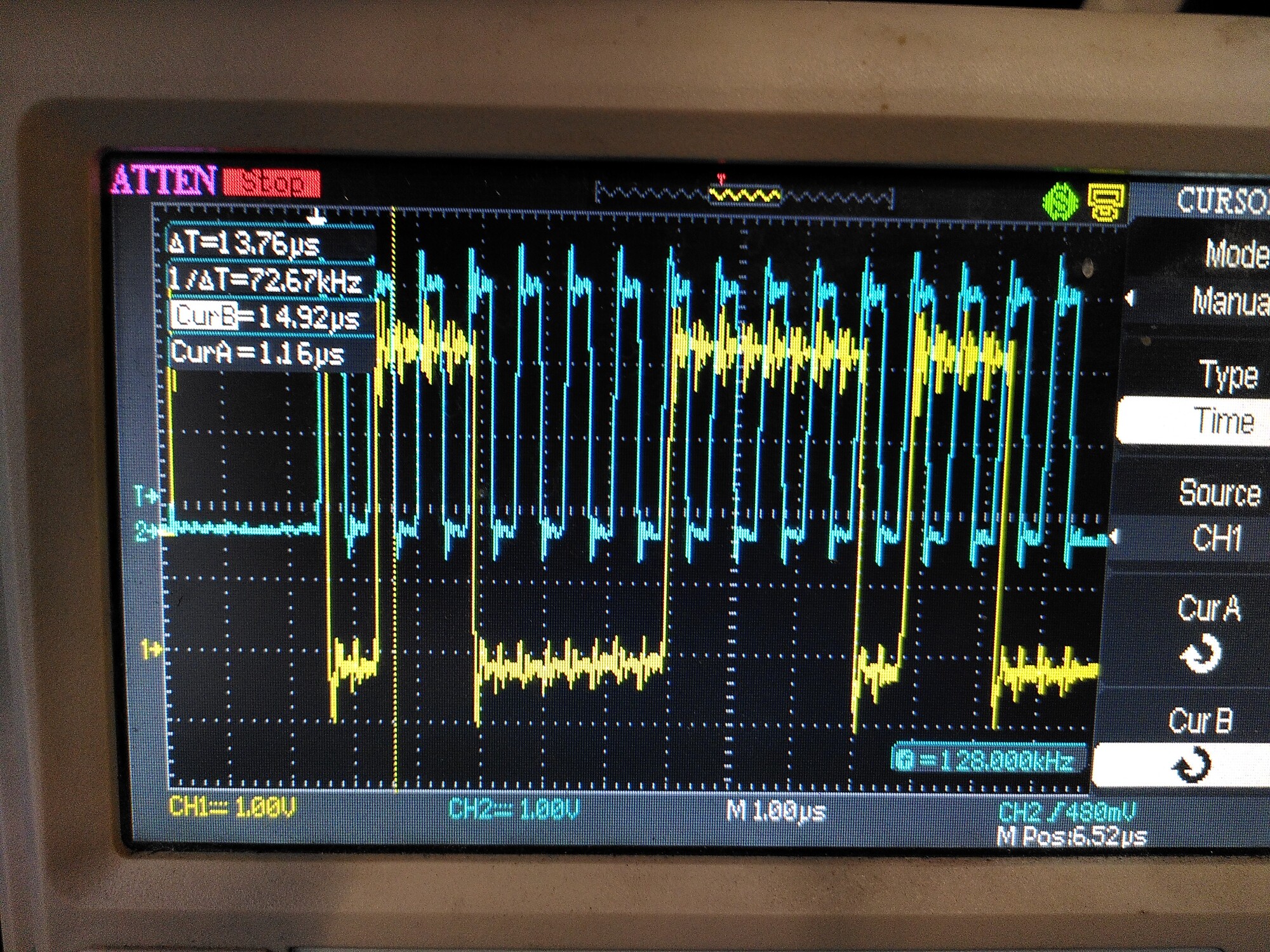
The first issue seems to be that there is a lot of ringing on the clock signal SCK - and it is coupling onto the MISO and MOSI lines. I guess that has to be wiring - I’ll try adding 50R series resistors.
SCK: (motors are off)
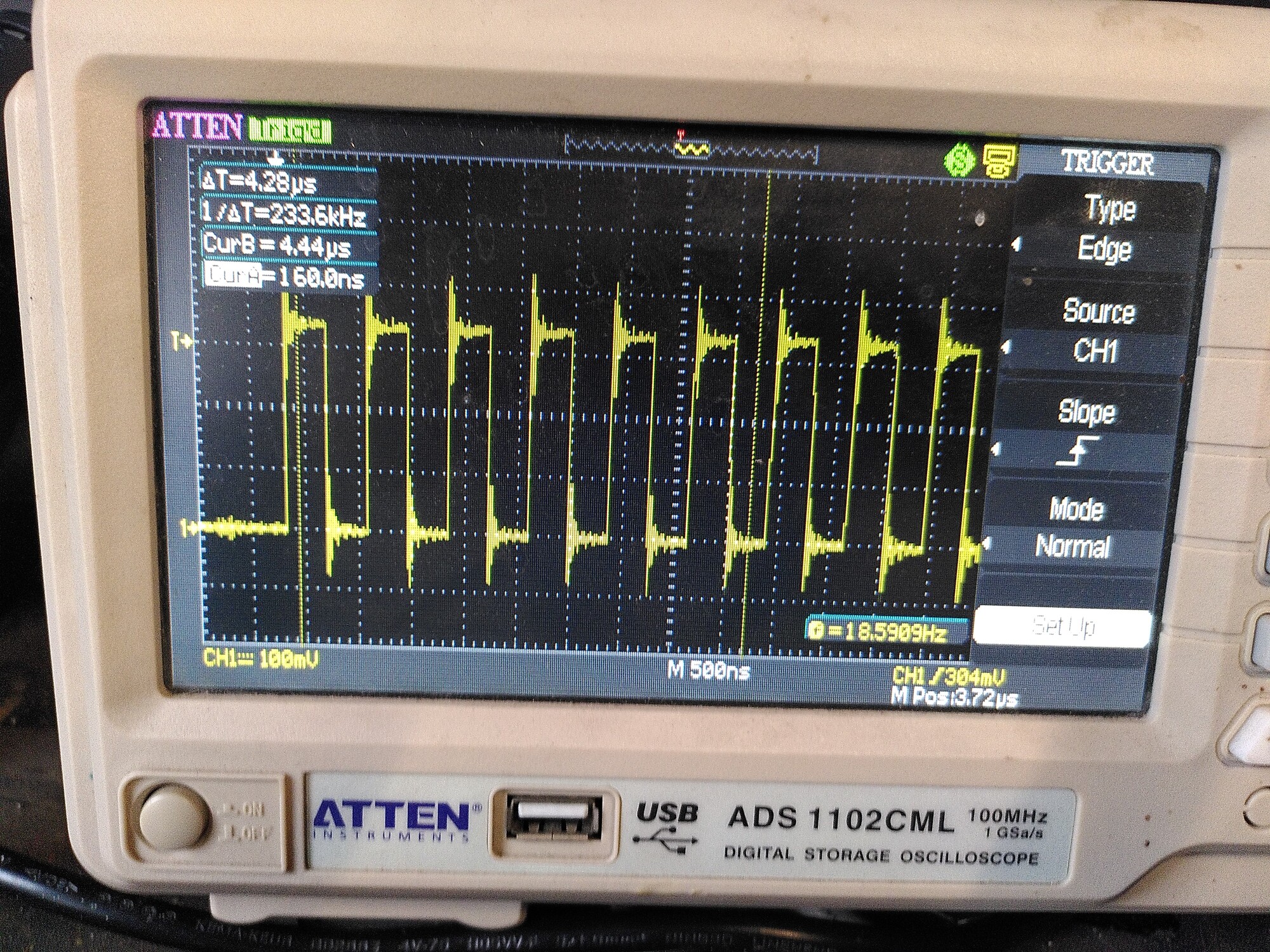
MOSI: (motors are off)
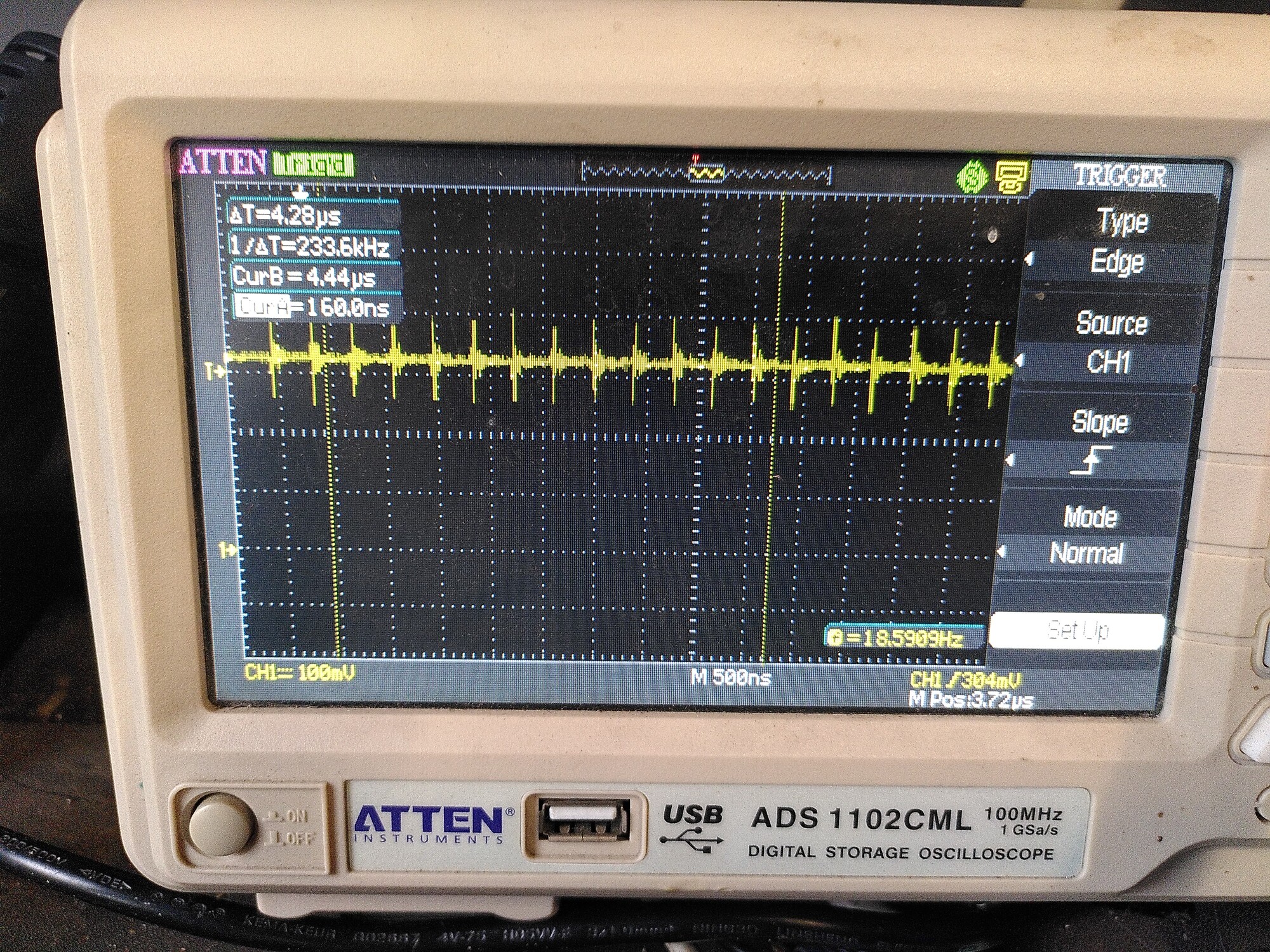
MISO: (motors are off)
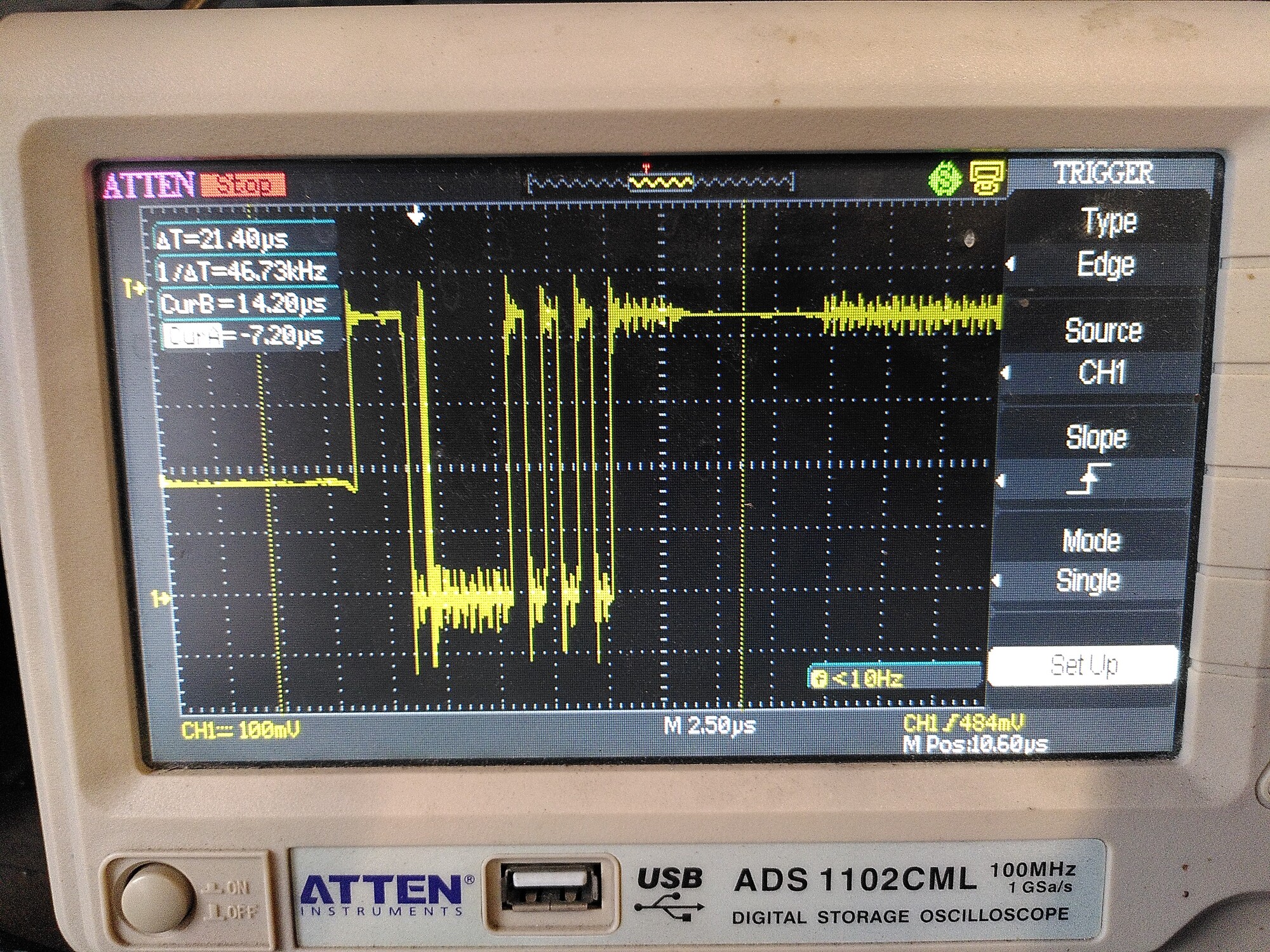
The second issue is that despite a ferrite on the motor wires, inverter switching noise is being coupled to all of the lines. The effect of that seems to be to throw the chip into some sort of ‘sulk’ state, where it sets its error bit high and keeps it there until a power cycle of the encoder itself.
This only happens when the motor is on, and it happens more quickly when the VBus voltage is higher. Above 20V it drops out in about 1 minute on average - above 30v it drops out in 10 seconds or so.
I can’t see how adding series resistors would help with this second issue.
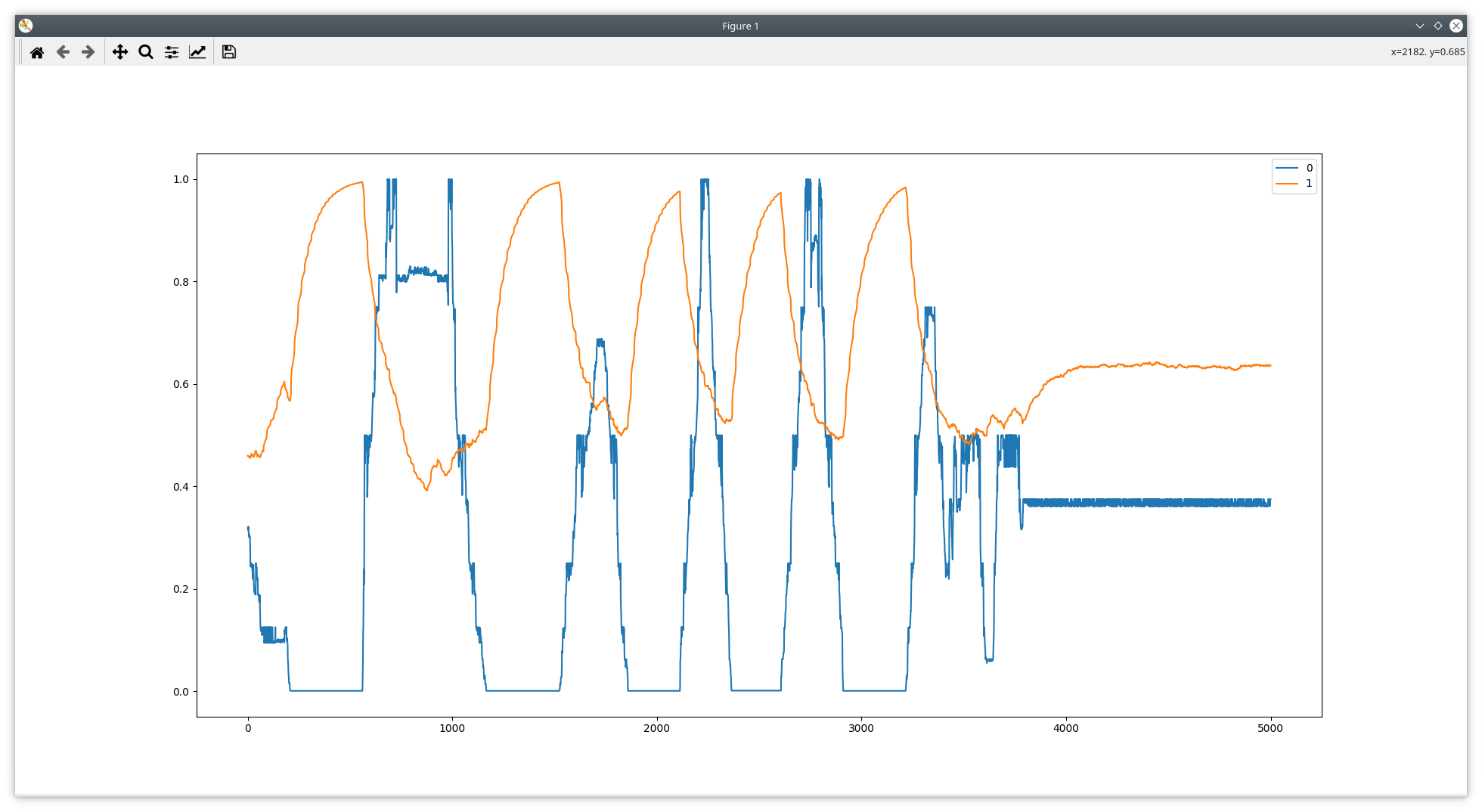
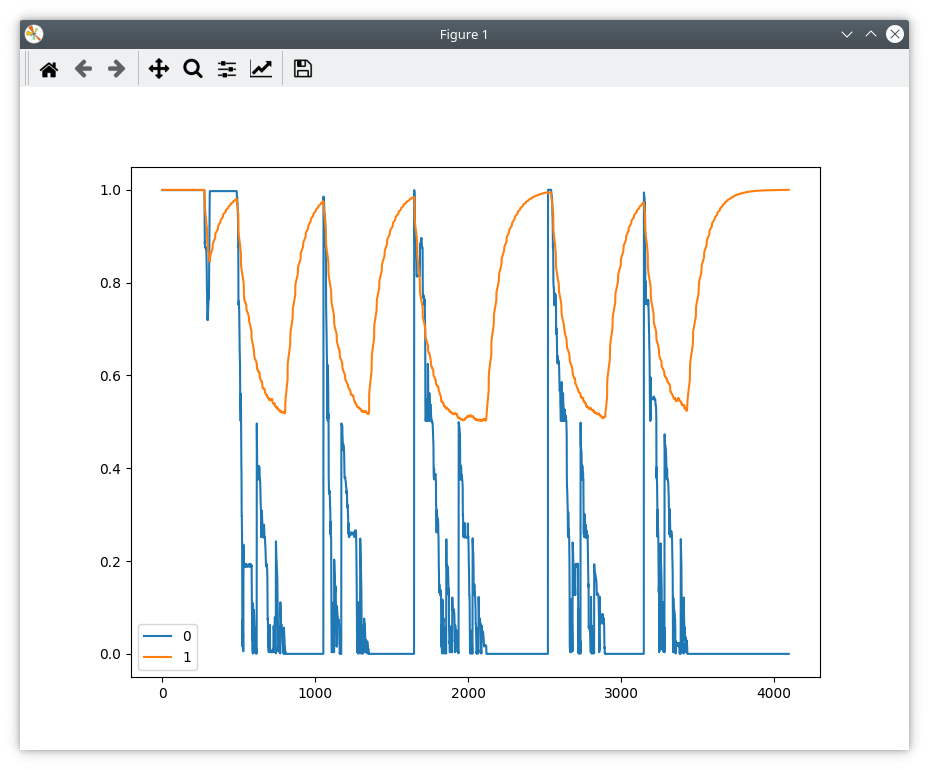
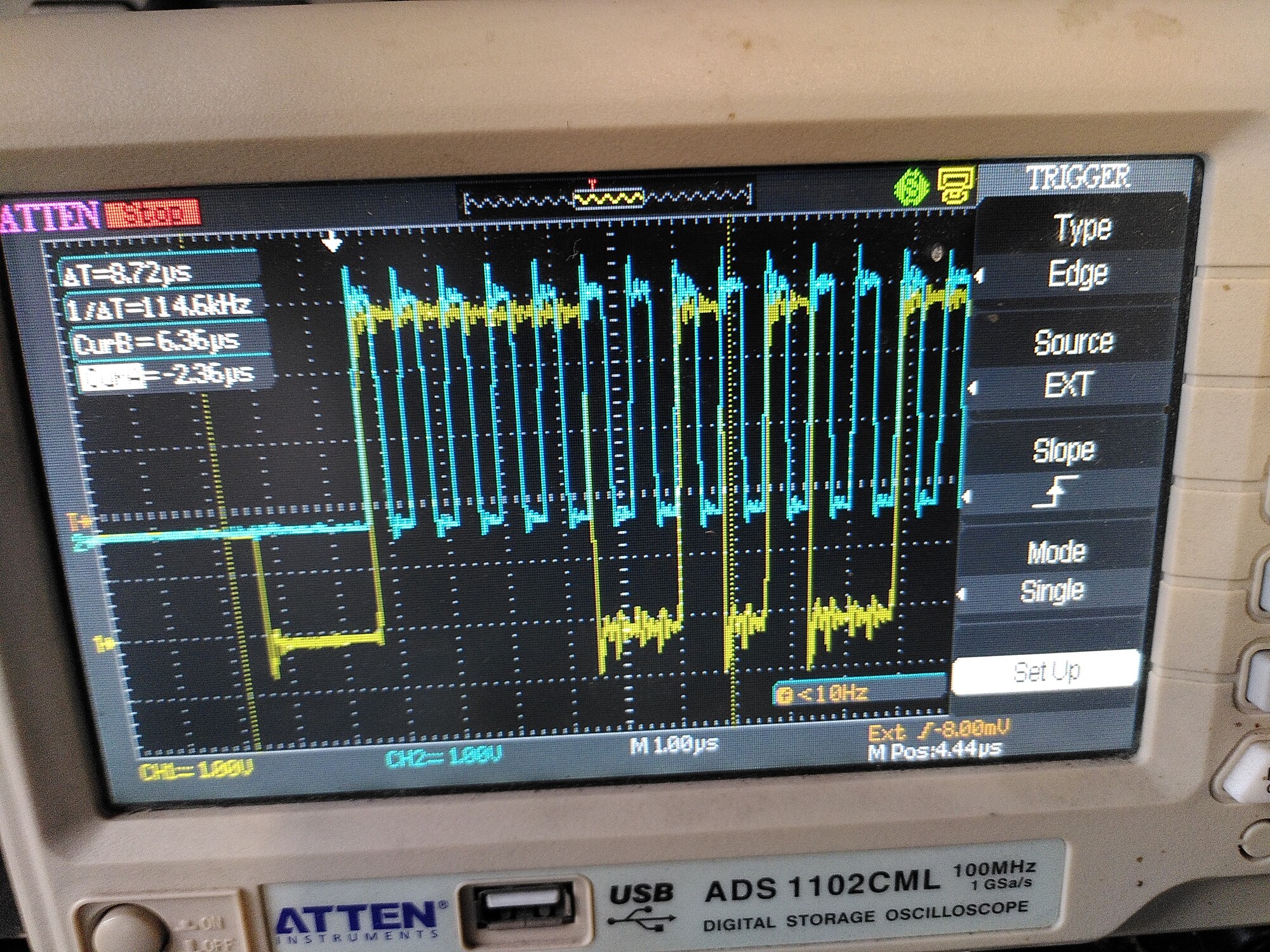
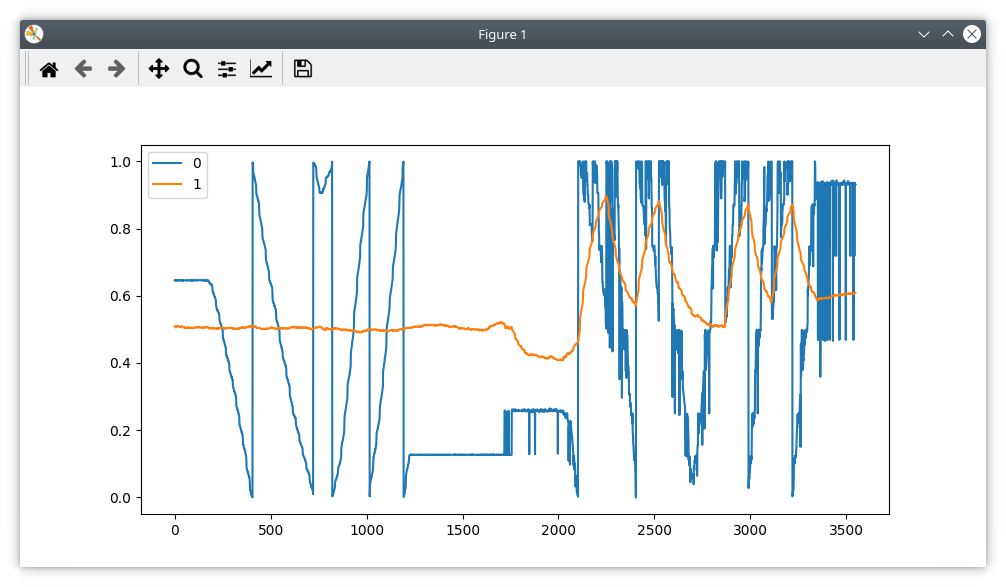
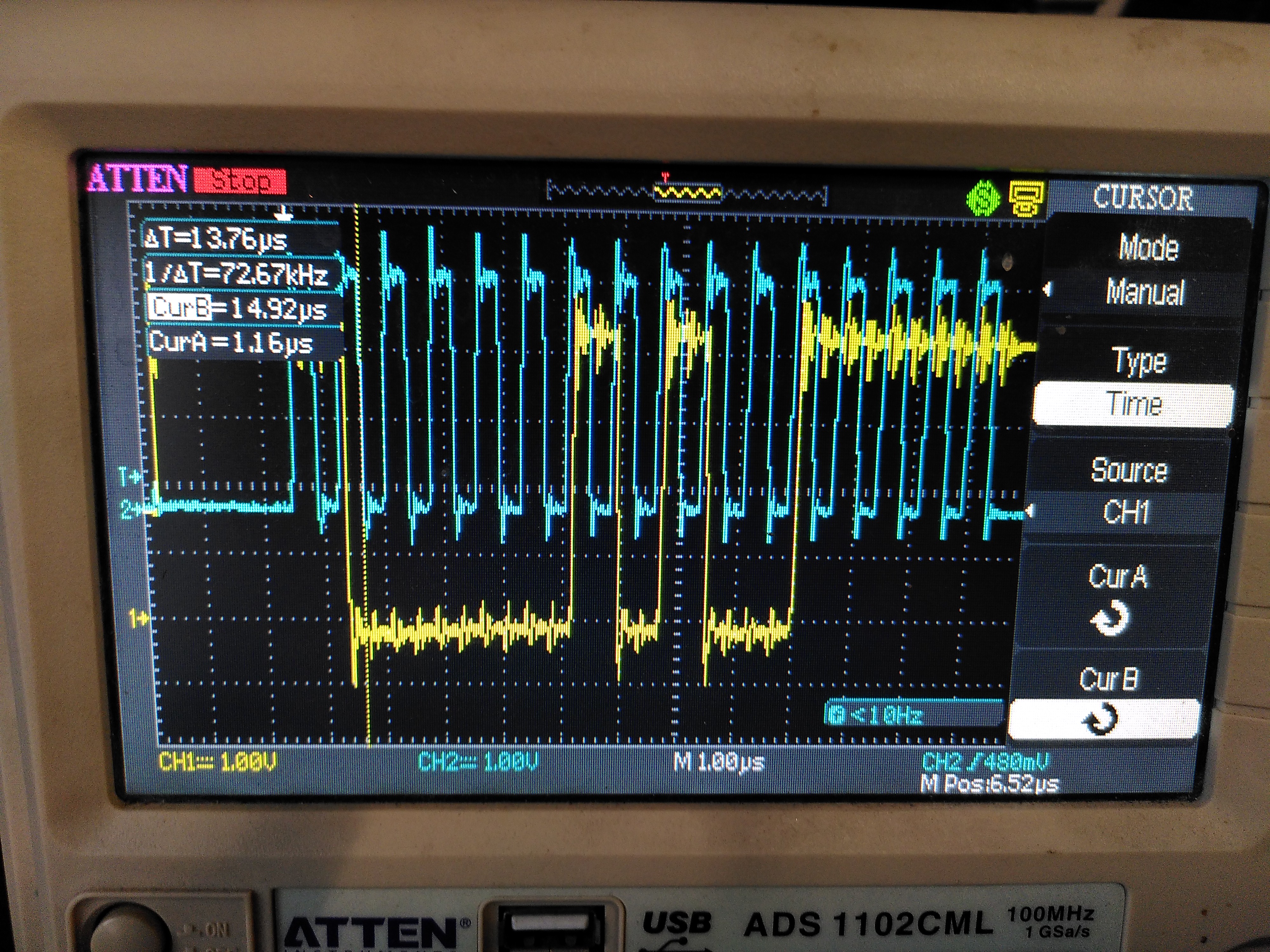
No error (note the bit at the cursor is low - that seems to be the error flag):
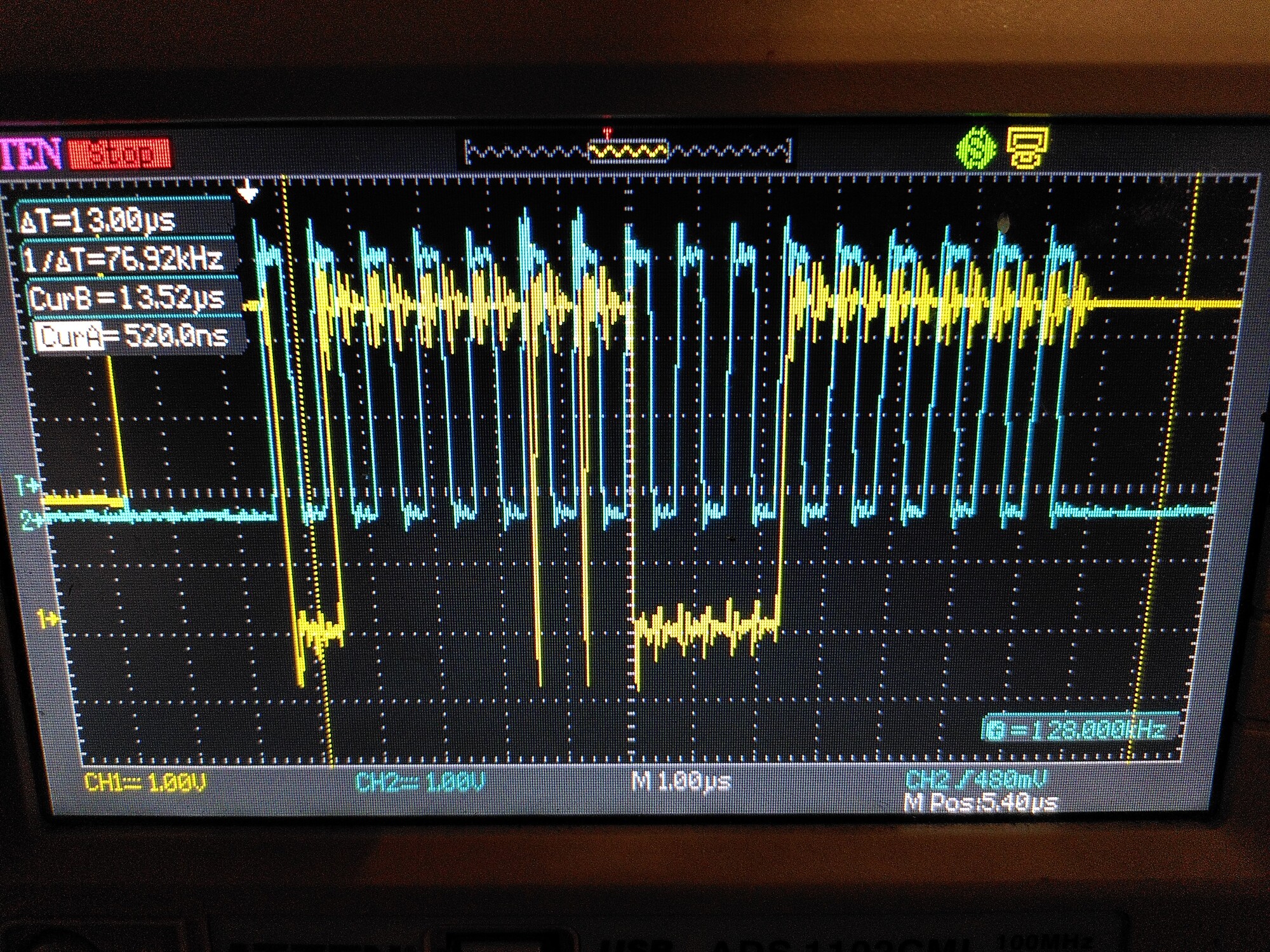
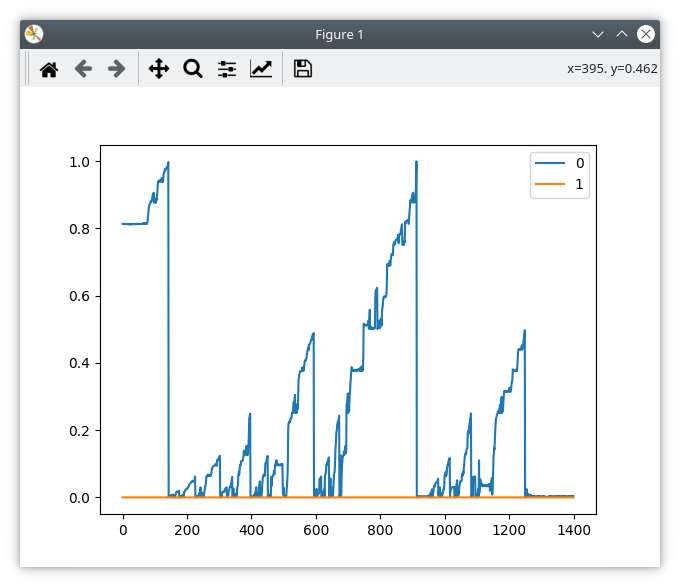
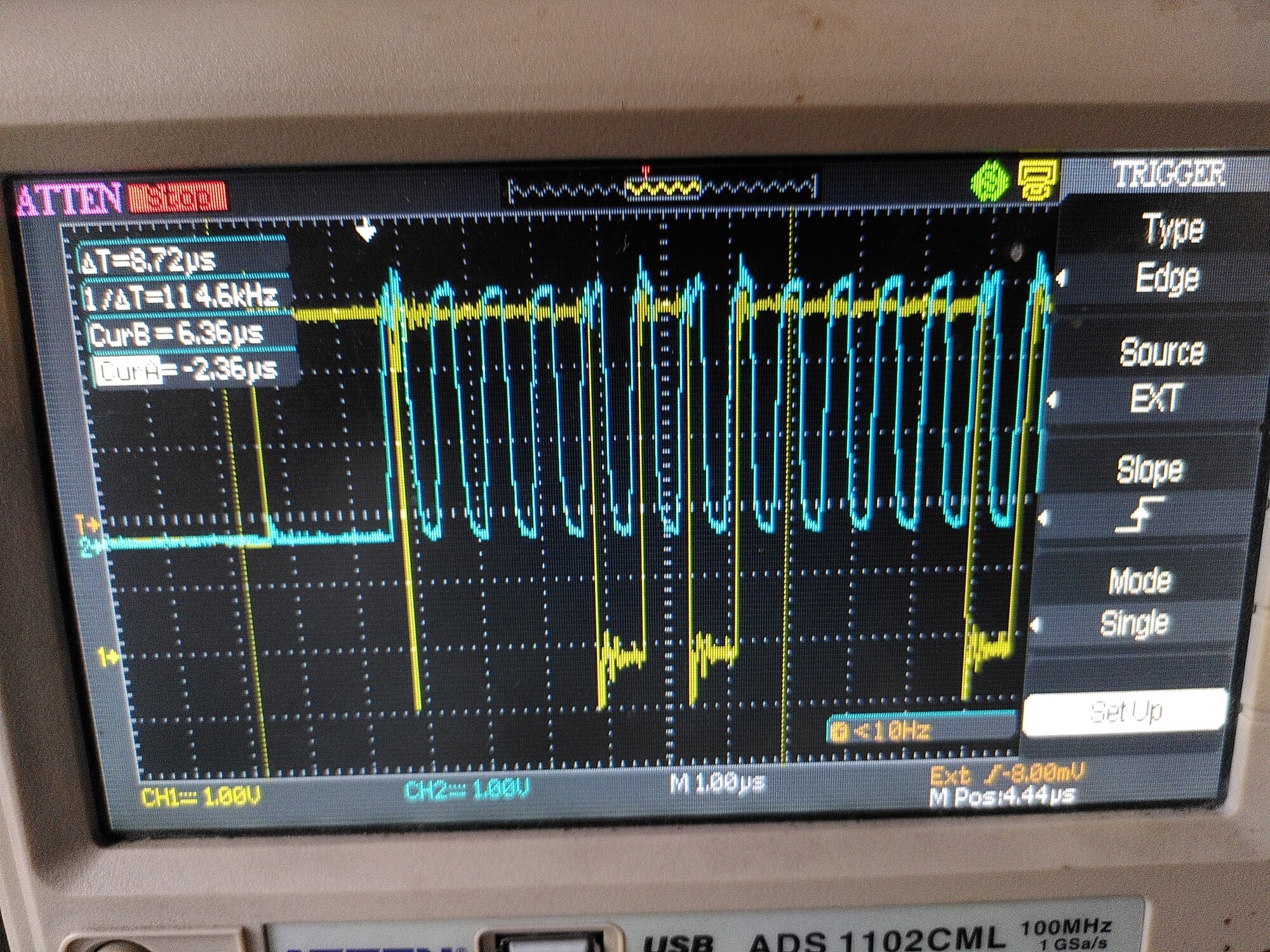
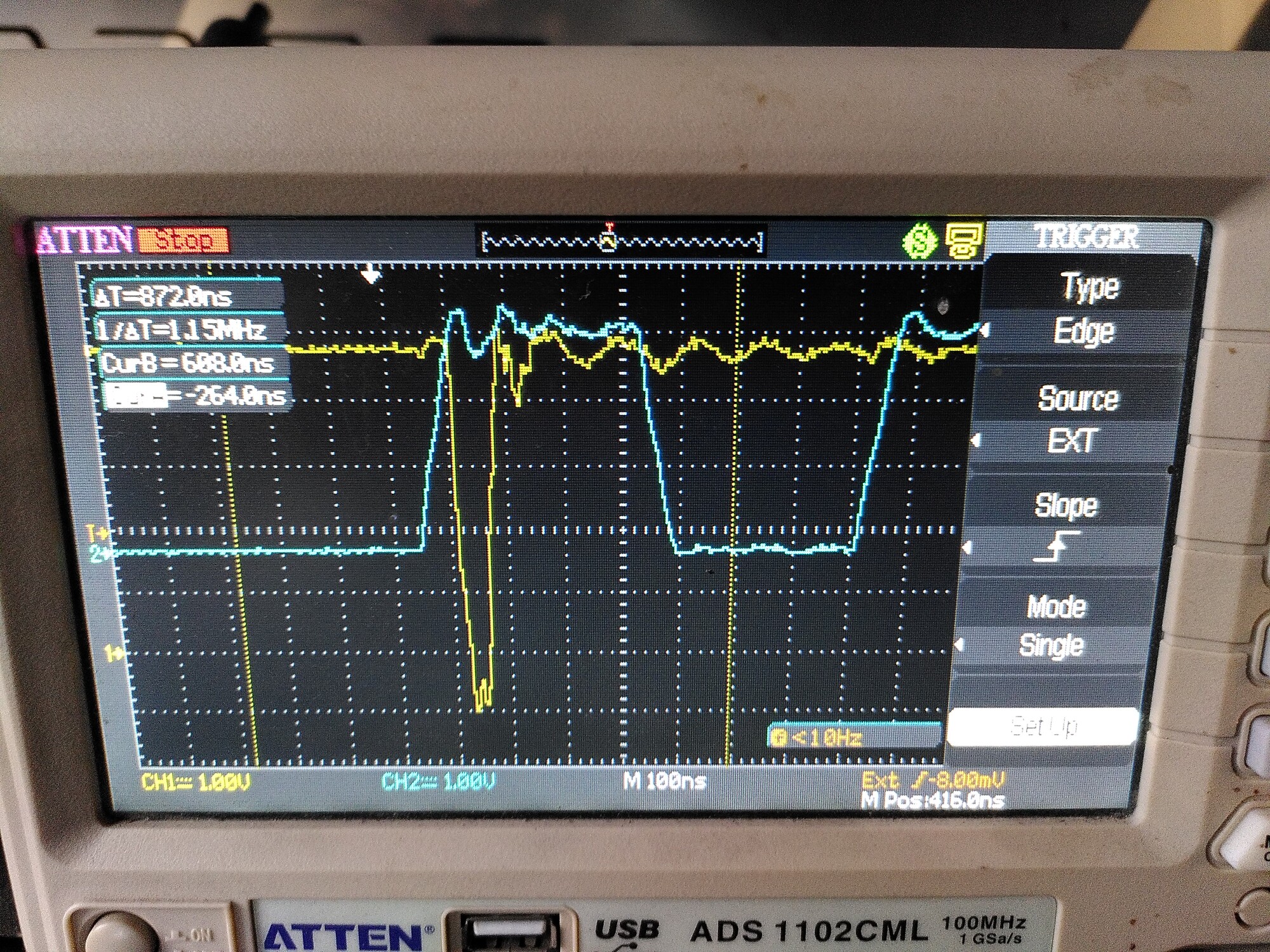
If I turn on PWM (torque mode, zero demand) then I see a nasty ringing on both lines:
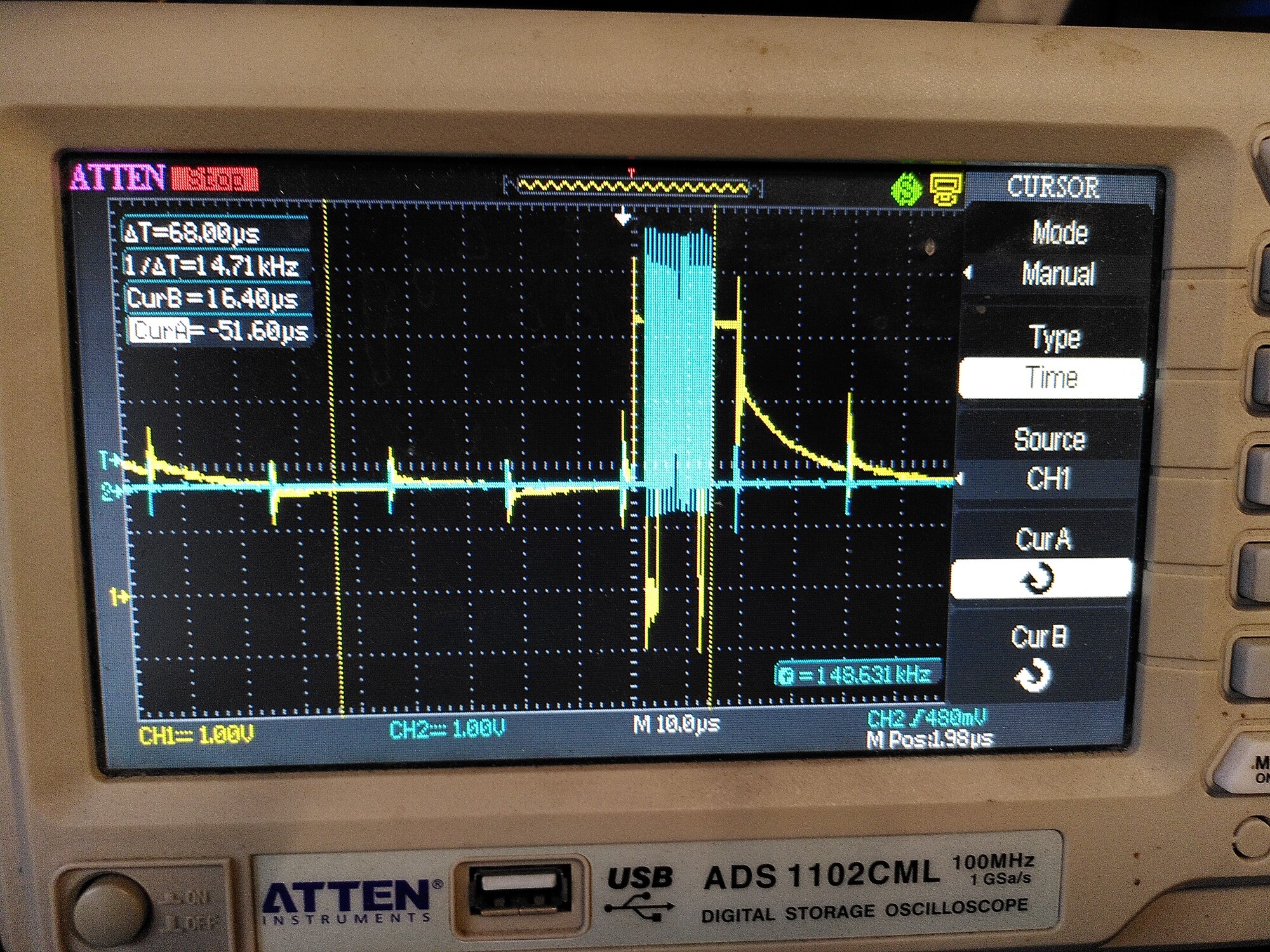

Then eventually the error bit gets set until I reset the power (clear errors or odrv0.reboot is not enough) .
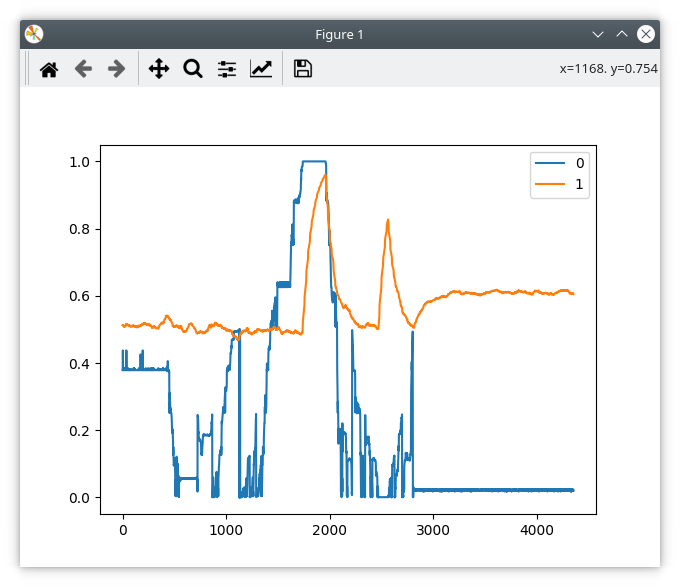
Interestingly, the position data is still there, but it is now being ignored by the ODrive.