As an alternative to the above, could one consider commands that could read (or even write) multiple values in one go? For instance, reading the position of both axes etc. I imagine this would allow latency due to the bus to be further reduced.
Would it be challenging to modify the codebase to support such a feature?
300 microseconds is pretty typical for the USB bus drivers on a host PC. I don’t think you can expect to cut this down very significantly.
Sending multiple commands in one package is something we wish to do. But we don’t have support for that yet. A general packet batching feature would be a nice way to go about it, then any set of commands can be batched together at the transport layer.
Feel free to dig into it. @Samuel may have some comments as well.
Thanks for the information. I do not have experience in USB programming, but I’m willing to give it a go anyway so maybe I’ll learn a few things along the way.
One question that comes in mind is how the packet batching would be architected from the API viewpoint, i.e. would there be a function that accepts multiple arguments, each corresponding to an endpoint (or endpoint/value pair for writing), and would then return corresponding values (if any)?
I would start looking at remote_endpoint_operation in protocol.py. Start by separating the packet formatting of the data from the transmission logic.
Then see if you can pack up multiple packets into a meta-packet. Then send this packet. Add the logic on the firmware side to decode the meta-packet and make a loop to call the original decode operation for each sub-packet.
How to handle the response for each sub-packet I’m not so sure. If the responses are limited in length, you could allocate a buffer for each sub-response, then pack them up to a large response.
Ok so it seems to me that a meta packet would contain full packets, together with their seq_no, crc value and any other bells and whistles that get added to the regular packet. For the receiving end to be able to break down individual packages, the length of each individual package would need to be specified. But since this is not part of the protocol spec, adding it would break the protocol.
Am I thinking in the right direction? Or is there an alternative? The protocol spec mentions a stream format but I’m not sure how they are related.
Actually yeah you can just use the stream protocol. We already have a packet-over-stream-over-usb(packets) implementation, so you would just have to make some mechanism to defer sending the USB stream buffer until it has filled more.
Ok I get it. I’m thinking having a delay(n) packet that would be sent first and would cause the next n packets to be sent in a batch.
Just one question: Is it currently safe to enable the stream-based protocol for regular odrivetool communication? I’ve been looking on Github and saw that there are some issues with it.
I think it boils down to remote_endpoint_operation always waiting for a reply before it returns.
If you change this function to spawn a background thread and immediately return a Future for the result, you may already get a significant speedup with the packet based version.
Better yet would be a single thread that takes care of all pending operations so you don’t have to spawn a new thread every time. This thread would have the same lifecycle as the one in start_receiver_thread.
If that’s not enough, using the stream-based protocol might indeed also help. The issue you linked is from January so I don’t know how relevant it still is since a lot has changed in the firmware since then.
BTW if you find Python’s synchronization primitives unsatisfying (as I did because they don’t allow you to wait on different kinds of events at the same time), you can use the stuff from here.
Thanks for the information @Samuel . After your suggestion (and having just received my ST-Link programmer ) I reflashed my ODrive with CONFIG_USB_PROTOCOL=native-stream , but after that I am unable to access it from odrivetool:
ODrive control utility v0.4.6
Waiting for ODrive...
USB discover loop
ConfigurationValue 1
InterfaceNumber 0,0
EndpointAddress 130
InterfaceNumber 1,0
EndpointAddress 1
EndpointAddress 129
InterfaceNumber 2,0
EndpointAddress 3
EndpointAddress 131
Kernel Driver was not attached
EndpointAddress for writing 3
EndpointAddress for reading 131
Connecting to device on USB device bus 20 device 5
Please connect your ODrive.
You can also type help() or quit().
no response - probably incompatible
USB discover loop
USB discover loop
USB discover loop
Ah yeah now odrivetool needs to treat the device as a serial port, otherwise it will still try to use the packet based protocol. Try to run odrivetool --path serial:[/dev/ttyWhatever], where /dev/ttyWhatever is the serial port device that corresponds to the ODrive. See odrivetool --help for more info:
To select a specific serial port:
--path serial:PATH
where PATH is the path of the serial port. For example "/dev/ttyUSB0".
You can use `ls /dev/tty*` to find the correct port.
You can combine USB and serial specs by separating them with a comma (no space!)
Example:
--path usb,serial:/dev/ttyUSB0
means "discover any USB device or a serial device on /dev/ttyUSB0"
However take this with a grain of salt because I haven’t tried this in a while.
Otherwise you can also hack usbbulk_transport.py to treat USB as a stream-based transport, by adding lines analogous to here
This is quite disappointing as with a 1.6ms latency even with multiple reads I’m way out of my application limits (I’d like a ~500Hz update rate, and I’m reading a couple other sensors and making some computations as well).
I ordered a CAN Bus transceiver and I’m gonna try CAN-Bus next
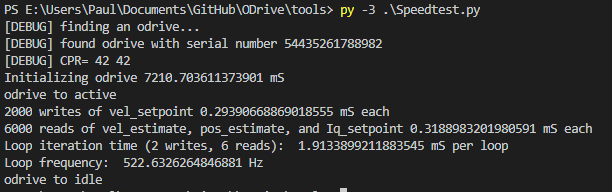
I’m also seeing high latency for read/write ops. It seems to average about 1.15 mS for read, 1.21 mS for write (see Python cProfile lines below, there were 3033 reads and 1014 writes in a roughly 5-second run.)
For every loop, we write 2 values (axis{0,1}.vel_setpoint) and read 6 values (axis{0,1}.{Iq_setpoint, pos_estimate, pll_vel}). That limits our maximum update rate to about 100 Hz, which makes it hard to have any kind of tight feedback loop in software.
A “set all” and “read all” command might be a better way to do the API.
This is on an nVidia TX2 board, with 6 64-bit ARM cores.
So we recently discussed this issue on the ODrive Discord. Here is sort of a summary:
Full Speed USB has a frame period of 1ms. Interrupt transfers and Isochronous transfers are initiated once per frame, with guaranteed latency. However, we use bulk transfers, which use up the “unallocated” bandwidth when the bus is otherwise idle. So the transfers may be initiated at any time: but there are no guarantees.
We found (at least on the machines we tested) that the bulk transfer had the lowest latency, because of this “unscheduled” attribute. Specifically: “Data are transferred in the same manner as in Interrupt Transfers, but have no defined polling rate. Bulk Transfers take up all the bandwidth that is available after the other transfers have finished. If the bus is very busy, then a Bulk Transfer may be delayed.”
So if there is no other traffic on the bus, we get better than 1ms latency, but if there is other heavy traffic on the bus, or if the host doesn’t really bother being timely about the bulk transfers, then there will be more latency
I am pretty sure that the latency on the ODrive side is extremely short, on the order of 10-100 microseconds.
On my Windows 10 machine it benchmarked a 1-out 1-response (2 packet) sustained full cycle time of 250 microseconds. So around 4000 full request-responses per second.
So if you get much worse latency than this, I would check:
Is there other traffic on the bus?
Does your platform not bother to be realtime about bulk transfers?
In the future we may upgrade to USB High-Speed (USB 2.0). This has 125 microsecond micro-frames, which lets us guarantee 125 microsecond latency Interrupt transfers.
@Wetmelon glad to see you got good results. We’re running on Ubuntu 16.04 on a NVIDIA TX2, and the oDrive is the only thing hooked up to USB. I wonder if it’s an ubuntu thing or an ubuntu+arm64 thing…
I would say trying to reduce the USB packet latency is a workaround at best.
The root problem here is that for a single variable write we do a complete round-trip on USB.
This can be fixed by implementing the following two things (in combination):
make remote_endpoint_operation asynchronous or “fire-and-forget”
transmit multiple commands in the same USB frame. As a temporary solution this can be achieved connecting to the ODrive via the COM-port interface.
So I went ahead and implemented a simple futures mechanism using some of the classes included in fibre. There were two aims at this point:
Make property writes fire-and-forget. In my case this almost halved the time spent in a property write (from 390μs to ~180μs), as would be expected.
Make property reads optionally return a future instead of waiting for the actual value to be retrieved from the Odrive. To measure whether this had any effect in latency I stacked a bunch of read commands and stored their returned futures in an array, and then went on and read them one by one. The resulting latency was slightly increased from 390μs to 420μs (probably due to the futures mechanism overhead).
(partial) test code:
import sys
import inspect
from timeit import Timer
import odrive
import unittest
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
odrv = None
REPEAT = 200
SAMPLES = 64
def time_read_current_limit(samples=SAMPLES):
futures = []
for _ in range(samples):
futures.append(odrv.axis0.motor.config.current_lim_future) # just some property
for f in futures:
f.get_value()
class TestTiming(unittest.TestCase):
def setUp(self):
global odrv
odrv = odrive.find_any()
def runTest(self):
fset = [f for name, f in inspect.getmembers(
sys.modules[__name__]) if inspect.isfunction(f)]
for f in fset:
fn = f.__name__
if fn.startswith("time"):
logging.info("Testing "+fn)
logging.info(Timer(lambda: f()
).timeit(number=REPEAT)/float(REPEAT)/float(SAMPLES))
As seen above the futures functionality is currently implemented as property aliases; to get a property to return a future, you append the string “_future” to its name, e.g. odrv0.vbus_voltage_future will give you a Future instance which you can query for the value using get_value(). I’m not sure if this is the ideal way to do this, but that’s what I ended up with.
What’s missing here is obviously a mechanism to defer sending packets and stack them up altogether so that they can be sent in one go over USB. Perhaps that should give a measurable drop in latency.
The tests mentioned above were performed on a Macbook Pro with the odrive connected directly to the computer’s USB port. Tests with the Raspberry Pi pending.
I really like the concept! Now code that doesn’t need the response right away can be way more efficient. Also I see how it can be a very neat way to interface to an underlying batching mechanism that can serve to use the USB bandwidth better by using larger packets, when/if we were to add that.
I don’t think I have the bandwidth (pun intended) to have a look at what you have made at the moment, but I’ve added it to the roadmap to take a look at later.
 ) I reflashed my ODrive with
) I reflashed my ODrive with